RAG是拐杖——「參數知識注入」把它扔掉了

清華大學的研究團隊剛剛解決了AI最頑固的問題之一——而答案比任何人預期的都要優雅。
你用過的每一個AI聊天機器人,其實都在作弊
有一件事AI產業不會大聲宣傳:大多數AI助手其實並不真正知道任何事情。
當你問一個現代AI聊天機器人關於近期事件、公司內部文件或專業領域的問題時,它並不是在從深厚的理解中提取答案。它要麼從過時的訓練數據中猜測——有時自信地猜錯——要麼在回答前匆忙查找資料。第二種方法有個名字:RAG,檢索增強生成。過去幾年,它一直是業界應對AI知識問題的萬能膠帶。
RAG就像開卷考試。AI不需要學習。它只是被允許帶筆記進場。在回答你的問題之前,它先跑一次搜尋,抓取一些相關文件,當場閱讀,然後嘗試總結它找到的內容。每一次。每一個查詢。
它能用。但它是一根拐杖。而來自清華大學的八位研究員——岳寶慶、蘇維航、艾欽耀、唐宜晨、王暢悅、康嘉誠、詹靖濤、劉奕群——剛剛造出了一個能把這根拐杖扔掉的東西。
這根拐杖哪裡出了問題?
在介紹解決方案之前,讓我們誠實地說清楚RAG的不足之處。
太慢了。 每次查詢都要先觸發一次檢索,AI才能開始思考。你在等一個搜尋引擎,然後才能得到答案。
太淺了。 AI是在閱讀,不是在學習。它對檢索到的材料沒有更深的理解——它只是在匆忙瀏覽從未見過的筆記,然後希望一切順利。
太脆弱了。 檢索到錯誤的文件就意味著生成錯誤的答案。垃圾進,垃圾出——以搜尋引擎的速度。
規模化成本高昂。 為數百萬次查詢處理長篇檢索文件,累積起來是巨大的計算成本。
顯而易見的替代方案——真正重新訓練AI學習新知識——聽起來更好,但在實踐中往往更糟。重新訓練一個大型模型需要數週時間,計算費用高昂,還有災難性遺忘的風險:模型在吸收新知識的同時開始失去它原本已知的東西。這就像每次公司政策改變就把你最優秀的員工送回大學重讀。
所以這個領域一直困在一個令人不舒服的中間地帶。一邊是RAG——更新快,但知識整合淺。另一邊是重新訓練——整合深,但慢、貴、有風險。
透過DMoE實現的參數知識注入,就是走出這個死胡同的出口。
核心概念:把知識做成可插拔的模組
DMoE代表解耦混合專家模型。名字聽起來很技術性,但概念卻美得簡單。
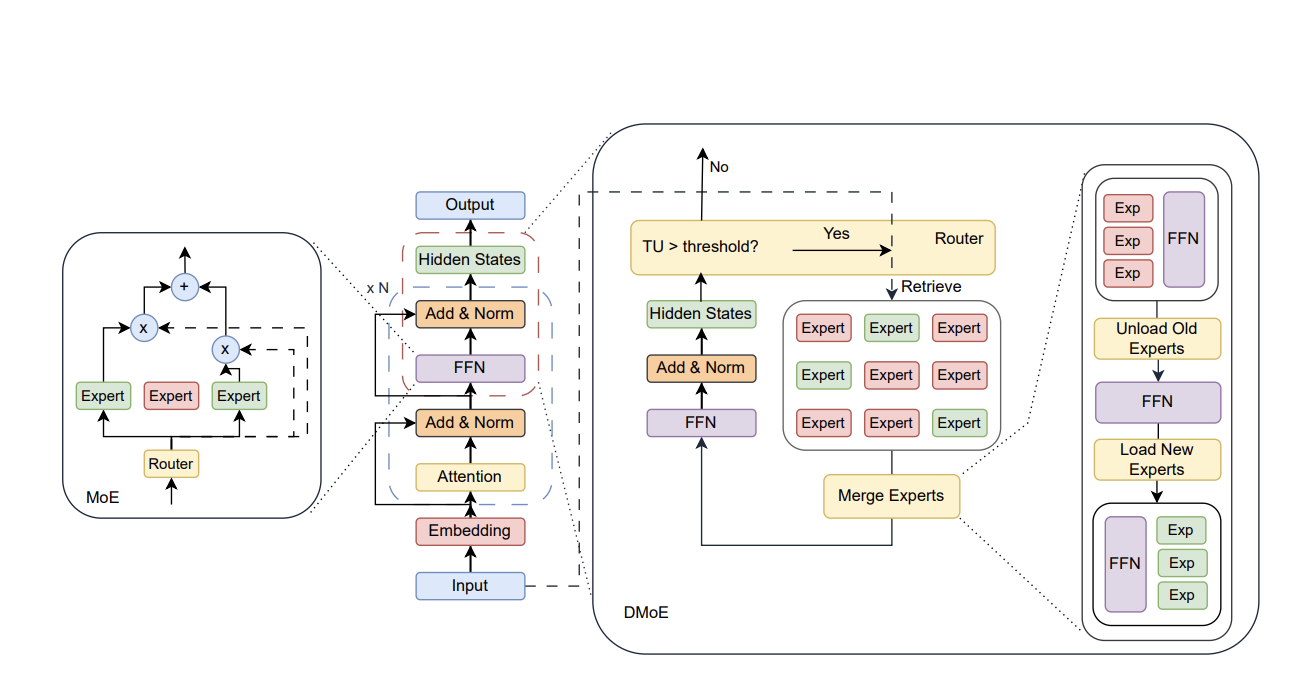
圖2:密集模型、傳統MoE與DMoE的架構對比。傳統MoE將前饋層替換為與模型緊密耦合的路由器-專家網路。DMoE則將路由器與專家完全解耦於凍結的基礎模型之外——推理時按需檢索並更新相關專家模組,實現自適應、非破壞性的知識整合。
把你的AI想像成一位技藝精湛的廚師。多年的烹飪訓練已經融入了他的直覺——那就是基礎模型。現在你希望這位廚師也能精通川菜、法式糕點和純素料理。
重新訓練的方式: 讓廚師回去廚藝學校讀六個月。貴、慢,而且他可能在過程中忘記了一些原有的廚藝。
RAG的方式: 每次烹飪時遞給廚師一本食譜書。他可以照著做,但他並不是真正的川菜廚師。他只是一個很會讀書的人。
DMoE的方式: 給廚師三個短期、專注的強化訓練——每種菜系一個——讓他把每一個都內化為獨立的技能組合。點了川菜,川菜專長啟動。需要法式甜點,糕點知識上線。廚師的核心廚藝從未改變。新的專業知識只是疊加在旁邊。
這就是參數知識注入。每個專家模組是一小塊輕量級的訓練知識——從特定的文件、主題或資料集中構建——它存在於主AI模型之外,但在被呼叫時會真正被吸收進它的參數中。不是從小抄上讀取。而是真正地知道。
DMoE的三個特別之處
核心AI永遠不被觸碰
這是最重要的一點。當你透過DMoE添加新知識時,基礎模型完全被凍結。不需要重新訓練。沒有遺忘的風險。沒有停機時間。沒有六位數的計算費用。
每個專家模組是一個小型訓練適配器——使用一種叫做LoRA的技術構建——編碼了一個特定的知識塊。想添加最新的醫學研究?訓練一個小模組。想更新公司的內部政策?換掉那一個模組。其他一切保持原樣。添加知識現在就像安裝一個應用程式一樣簡單。
AI知道什麼時候需要幫助
DMoE不會盲目地為它生成的每一個字都啟動專家模組。那樣會適得其反。相反,它實時監控自己的信心水平——逐個詞元地監控。
就像一個GPS,大多數時候信任自己的地圖,但一旦偵測到前方堵車,就自動切換到即時路況數據。AI正常生成答案——只有當它察覺自己進入了不確定的領域時,才會向專家模組求助。
這種不確定性的技術衡量標準叫做詞元不確定性——本質上是AI對下一個詞的概率分佈的熵:
當這個不確定性分數超過閾值 τ,路由器啟動。它對所有可用的專家模組進行快速關鍵字搜尋,挑選最相關的,然後把它們帶進來。當信心高時,AI獨自工作。乾淨、高效、智能。
一個聰明的技巧讓它保持極速
這是研究團隊需要優雅解決的一個問題。AI模型使用一個叫做KV快取的加速機制——本質上是它已處理內容的記憶,這樣在回答中途就不必重新計算。如果你在AI思考過程的多個節點附加專家模組,你會打亂這個快取並完全失去速度優勢。
DMoE的解決方案:只在AI處理流程的最後一層附加所有專家知識。在那個最後步驟之前的一切都保持快取和不變。專家知識在最後才疊加進來——就像一位專家對一份已經起草好的文件做最終審閱,而不是從頭重寫每一段。
結果:深度的參數級知識整合——以接近標準的推理速度。
數字不會說謊
研究團隊在四個嚴格的知識基準測試上運行了DMoE——HotpotQA、ComplexWebQuestions、Quasar-T和StrategyQA——使用兩個真實AI模型(Llama-3.2-1B-Instruct和Qwen2.5-1.5B-Instruct)作為基礎。
| 測量項目 | DMoE結果 |
|---|---|
| 回答準確率 vs. 基礎AI | 在全部4項基準測試中更好 |
| 速度 vs. 最佳RAG競爭者(FLARE) | 約快3倍 |
| GPU記憶體 vs. 傳統MoE主幹 | 7–8 GB vs. 26 GB |
| 每次回答時間 vs. 傳統MoE | 2–4秒 vs. 20秒以上 |
| 是否忘記原有知識? | 未偵測到任何退化 |
更聰明。更快。更便宜。更安全。同時做到。
這在現實世界中解鎖了什麼
醫療
醫院部署一個基礎AI模型。每個科室——心臟科、腫瘤科、急診科——獲得自己的專家模組。更新某個專科的臨床指南?換掉那一個模組。系統其他部分完全不受影響。
企業
你的公司AI助手把內部政策、產品規格和客戶歷史作為模組化知識包來攜帶。新季度,新定價表?一個模組更新。不需要IT項目。不需要重新訓練預算。不需要等待。
新聞與金融
媒體公司和交易公司每天推送新的知識模組——讓他們的AI真正了解時事,而無需持續重新訓練的成本或延遲。
教育
AI導師為每個科目和年級載入課程專屬模組,只啟動與每個學生問題相關的內容。個性化、深入且高效——全部來自同一個基礎模型。
那麼RAG真的死了嗎?
還沒——研究人員也沒有這樣聲稱。
當你需要在真正龐大、不可預測、不斷變化的語料庫中搜索時——比如開放網路——RAG仍然有意義。對於這種廣泛的檢索,搜尋引擎仍然是正確的工具。
但對於你希望AI真正知道而不僅僅是查找的結構化、特定領域或專有知識——DMoE是一個根本上更好的答案。這是一個攜帶圖書館借書證的AI和一個真正讀過那些書的AI之間的區別。
RAG一直是一個變通方案。參數知識注入才是真正的解決方案。
還在繼續改進的地方
研究團隊對開放性問題很坦誠。目前的路由系統使用關鍵字匹配(BM25)——快速實用,但並不總能捕捉到查詢的完整含義。未來版本可以使用更智能的語義搜尋來進行路由。管理非常大的專家庫——可能是數千個模組——將需要新的組織工具。雖然單層附加對速度很好,但未來的多層專家整合可能會解鎖更豐富的知識深度。
總結
AI一直有一個從出生就印在上面的知識到期日。每個模型知道訓練截止日期之前的一切——之後什麼都不可靠。
RAG試圖透過給AI配備搜尋引擎來解決這個問題。它有幫助。但它一直是一根拐杖——業界每個人都心知肚明。
DMoE把那根拐杖扔掉了。新知識被打包成輕量級模組,按需插入,並在參數層面真正被吸收——不需要觸碰基礎模型,不需要運行檢索流程,也不需要花幾個月重新訓練。
清華大學的研究團隊構建了一個用簡單語言描述起來幾乎太過乾淨的東西。但基準測試是真實的,架構已發表,結果不言自明。參數知識注入不再是研究幻想。它是一個可運行的系統——而且它剛剛讓RAG看起來非常、非常疲憊。
資料來源
- 岳寶慶、蘇維航、艾欽耀、唐宜晨、王暢悅、康嘉誠、詹靖濤、劉奕群(2026)。Decoupled Mixture-of-Experts for Parametric Knowledge Injection。arXiv:2606.14243。https://arxiv.org/abs/2606.14243
- arXiv完整論文HTML。https://arxiv.org/html/2606.14243
- The Moonlight — 文獻評述。https://www.themoonlight.io/en/review/decoupled-mixture-of-experts-for-parametric-knowledge-injection