10,300 to 1: How AI Crawlers Are Quietly Draining the Web Economy — And What Every Publisher, Lawyer, and Financial Analyst Must Do Now

The web has crossed a historic threshold. Bots now outnumber humans online — and AI crawlers are the biggest culprits taking without giving back.
The Alarming Ratio Nobody Is Talking About
Imagine a library where thousands of visitors photocopy every book on the shelf, but almost none of them ever buy anything or recommend the library to a friend. That is precisely what is happening to the modern web.
According to data published by Cloudflare Radar (May 31, 2026), Anthropic's Claude crawler holds a staggering crawl-to-refer ratio of 10,300:1 — meaning it scrapes 10,300 HTML pages for every single visitor it sends back to a publisher's website. OpenAI's GPTBot follows at 903.8:1, and Perplexity's bot at 192.9:1. In stark contrast, Google's Googlebot sits at just 5.2:1, and DuckDuckGo's DuckAssistBot at 1.5:1 — ratios that reflect the traditional, traffic-reciprocating model of the open web.
Bots Have Officially Outnumbered Humans on the Web
This isn't just about one infographic. On June 3, 2026, Cloudflare CEO Matthew Prince shared data confirming that automated requests now make up 57.5% of all HTML web traffic, with humans accounting for just 42.5%. Prince himself admitted: "Welp, that happened faster than I predicted." This is the first time in internet history that machines have held the majority of web traffic — and AI crawlers are a key driver of that shift.
Within verified bot traffic, AI crawlers account for 20.3%, with AI-search bots adding another 6.5% — meaning roughly 26.7% of all verified bot activity is now AI-related. Critically, 51.8% of AI crawler requests are for training purposes, not search or user assistance — and training crawlers generate almost zero referral traffic back to publishers.
Let that sink in: more than half of all AI crawling exists purely to harvest your content to train models. Not to send you readers. Not to credit your work. Just to take.
The Training Crawl Dominance
Cloudflare's deeper analysis reveals a troubling structural shift: training now drives nearly 80% of all AI bot activity, up from 72% just a year ago. Meanwhile, publisher referrals are falling. Google referrals to news sites dropped roughly 9% from January to March 2025, and fell as much as 15% by April 2025 — a decline that coincides directly with Google's expansion of AI Overviews powered by Gemini 2.0 and the rollout of AI Mode in the U.S.
OpenAI's GPTBot more than doubled its share of AI crawling traffic (from 4.7% to 11.7%), while Anthropic's ClaudeBot rose from 6% to ~10%. ByteDance's Bytespider fell dramatically from 14.1% to just 2.4%.
The Leaderboard of Crawl-to-Refer Ratios (May 2026)
| Platform | Bot Name | Crawl-to-Refer Ratio |
|---|---|---|
| Anthropic | ClaudeBot | 10,300 : 1 |
| OpenAI | GPTBot | 903.8 : 1 |
| Perplexity | PerplexityBot | 192.9 : 1 |
| Microsoft | Bingbot | 35.3 : 1 |
| Mistral AI | MistralAI-User | 28.3 : 1 |
| Yandex | YandexBot | 24.2 : 1 |
| Baidu | Baiduspider | 12.3 : 1 |
| ByteDance | Bytespider | 9.3 : 1 |
| Googlebot | 5.2 : 1 | |
| DuckDuckGo | DuckAssistBot | 1.5 : 1 |
Source: Cloudflare Radar, May 31, 2026
What Can Publishers Do?
Cloudflare has responded by launching new tools on its Radar AI Insights page, including:
- Crawl-to-refer ratio tables updated in near real-time
- Crawl purpose breakdowns (Training / Search / User Action / Undeclared)
- Industry-level filtering to benchmark your site against peers
- Pay-per-crawl mechanisms being explored to rebalance the equation
Publishers now have more data than ever to make informed decisions about which AI bots to allow, restrict, or block entirely via robots.txt or Cloudflare's bot management tools. The key insight: not all bots are equal. A bot with a 1.5:1 ratio is a partner; a bot with a 10,300:1 ratio is, economically speaking, a parasite.
The Bottom Line: The Case for Taking Back Control with On-Premise AI
The web's economy is being quietly restructured — and the numbers make it impossible to ignore.
As of June 3, 2026, bots now generate 57.5% of all HTML web traffic, with humans at just 42.5%. More than half of all AI crawling — 51.8% — exists purely for training. Training crawlers return almost zero referral traffic to publishers. The machine majority is here, and it is hungry.
Your Work Built Their Empire. You Got Nothing.
Let's be direct: your content was taken without permission, without credit, and without compensation — and it was used to build some of the most valuable AI products in history.
When Anthropic's ClaudeBot crawled 10,300 pages for every single visitor it sent back, it wasn't browsing. It was extracting. When OpenAI's GPTBot swept through at 903.8:1, it wasn't indexing for your benefit — it was feeding a commercial product that now competes with the very sources it consumed. When Perplexity scraped at 192.9:1, it was building an "answer engine" that presents your expertise as its own, with a citation so small and buried that most users never click it.
Your byline? Gone. Your years of expertise? Dissolved into a model weight. Your competitive edge? Repackaged and sold back to your own clients — or worse, to your competitors.
This is not a side effect. This is the business model. Training crawling now accounts for nearly 80% of all AI bot activity — up from 72% just a year ago. The entire architecture of modern AI is built on the systematic, industrial-scale extraction of human knowledge and creativity, with no opt-in, no royalty, no acknowledgement. The AI companies didn't ask. They just took. And the 10,300:1 ratio is the receipt that was never sent to you.
If Public Knowledge Is Already Being Taken — What About the Knowledge That Was Never Meant to Be Public?
And that brings us to a far deeper, more unsettling question — one that goes beyond bloggers and journalists and strikes at the heart of two of the world's most knowledge-intensive industries: law and finance.
The content scraped from the open web — news articles, blog posts, published research — was at least written with the intention of being read. But consider the professionals whose most valuable knowledge has never been published online at all:
- A senior litigation partner whose strategic instincts across 30 years of case work exist only in internal memos, client files, and institutional memory
- A private equity analyst whose proprietary valuation frameworks and deal intelligence live in internal models and confidential reports that were never meant to leave the firm
- A compliance officer whose nuanced interpretation of evolving regulations is embedded in internal guidance documents built over decades of hard-won experience
This is the knowledge that truly defines competitive advantage in law and finance. It cannot be Googled. It cannot be scraped — yet. But here is the chilling reality: the moment any of it touches a cloud-based AI tool — even casually, even in a single query — it enters an ecosystem governed by the same extractive logic we have been discussing all along.
The same AI giants that scraped the open web without credit are now offering enterprise tools. The same training pipelines that consumed public content without asking are hungry for more. The same companies sitting atop those 10,300:1 and 903.8:1 ratios are now knocking on the door of your law firm's document management system and your bank's research repository.
At its worst, Anthropic's ClaudeBot recorded 286,000 crawls per single referral in January 2025. A company that demonstrated it would crawl a quarter of a million pages before returning a single visitor is now asking for your trust with your most sensitive client data. The question writes itself: do you trust the same hands that took without asking to now hold what you can never afford to lose?
On-Premise AI: Keeping What Is Yours, Yours
On-premise AI deployment changes the equation entirely.
Rather than sending your most sensitive knowledge — client contracts, trading strategies, case precedents, internal research — out to external servers where data governance is opaque and training pipelines are invisible, on-premise AI keeps that intelligence inside your walls, under your control, subject to your compliance frameworks, and permanently out of reach of any crawl-to-refer ratio.
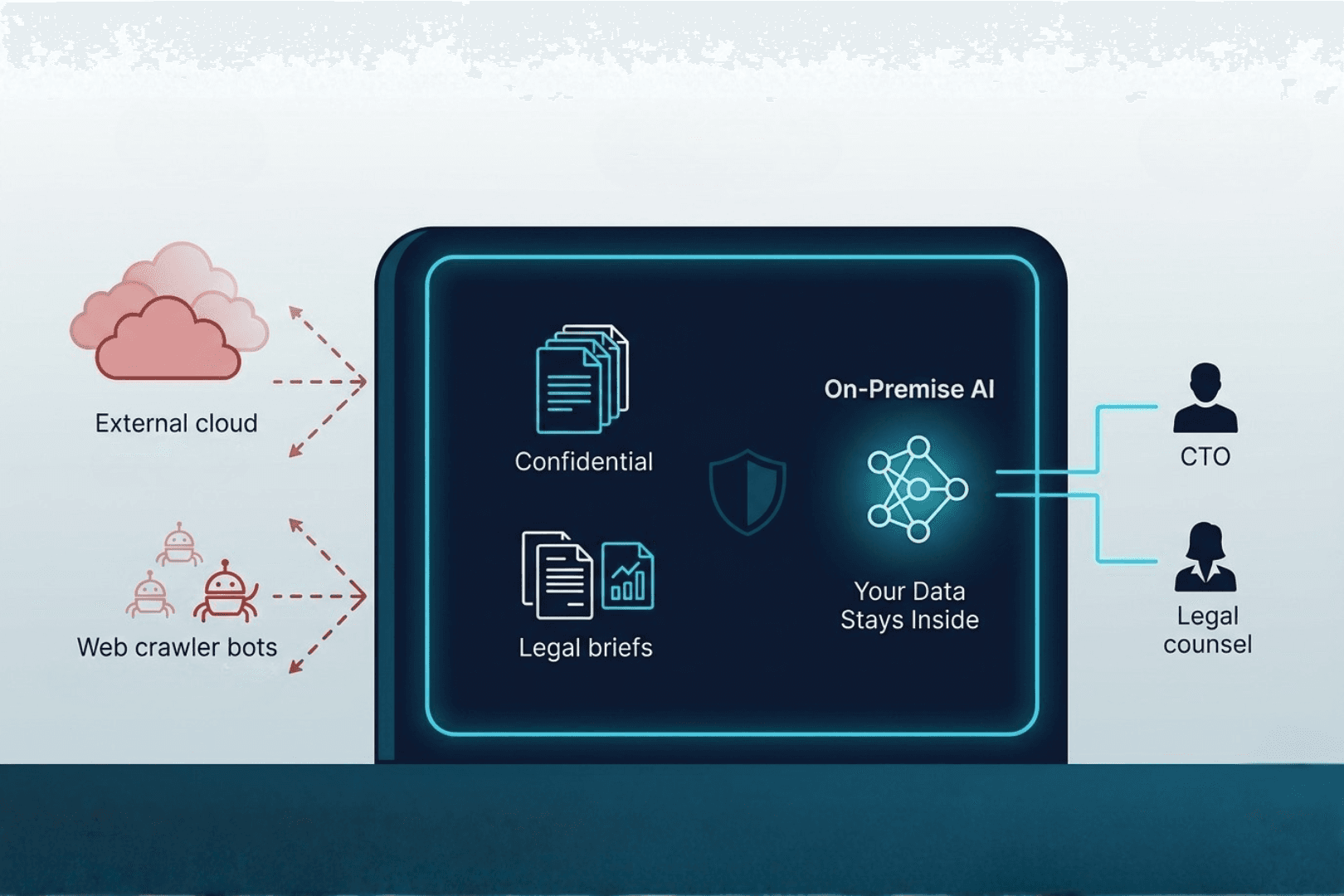
Consider what this means in practice:
- Legal firms can build AI systems trained on decades of proprietary case strategy — knowing that a 10,300:1 crawl ratio will never apply to their internal knowledge base. Client privilege stays privileged.
- Financial institutions can deploy models that reason over confidential portfolios and market intelligence, with zero risk of that data surfacing in a public LLM — especially critical given that AI-referred traffic to commercial platforms grew 393% year-over-year in Q1 2026, signalling how deeply AI has penetrated financial decision-making.
- Healthcare providers can leverage AI for diagnostics and research without patient data ever leaving a secured, audited environment.
- Enterprises can protect trade secrets, product roadmaps, and competitive intelligence from becoming tomorrow's training corpus — part of that 80% training-purpose crawl activity that is silently reshaping the web right now.
The lesson of the 10,300:1 ratio is this: the internet gave away its knowledge for free, and AI companies built empires on it. Industries that hold genuinely proprietary, high-value knowledge do not have to repeat that mistake. The open web didn't have a choice. You do.
On-premise AI is not a step backward — it is the strategic choice of organizations that understand the true value of what they know, and refuse to let it be crawled, scraped, and repackaged without consent, credit, or compensation.
The question for every CTO, General Counsel, and Chief Risk Officer is no longer "Should we adopt AI?" It's "Are we adopting AI in a way that protects what makes us irreplaceable?"
Sources
- Cloudflare Blog: AI Search Crawl-Refer Ratio on Radar
- Cloudflare Blog: The Crawl-to-Click Gap — AI Bots & Training
- Cloudflare Blog: AI Crawler Traffic by Purpose and Industry
Ready to evaluate on-premise AI for your organization?
We help publishers, law firms, financial institutions, and enterprises design AI governance strategies — including on-premise deployment that keeps proprietary knowledge inside your walls. Talk to our experts about compliance-aware AI adoption.
Learn more: AI Consulting services