Baidu's Unlimited OCR: The AI That Can Read an Entire Book in One Go

Introduction: OCR Just Got a Major Upgrade
Have you ever tried to scan a 50-page report and had your software choke halfway through? You're not alone. For decades, Optical Character Recognition (OCR) — the technology that turns images of text into actual readable text — has had a dirty little secret: it falls apart on long documents.
But that just changed. Baidu, China's leading tech giant, has just released a groundbreaking AI model called Unlimited OCR, and it does exactly what the name suggests — it reads documents with virtually no length limit, all in a single pass. No page-by-page chunking. No memory crashes. Just one smooth, continuous read from cover to cover.
The Problem: Why Long Documents Break OCR
To understand why Unlimited OCR is such a big deal, let's talk about why regular OCR struggles with long documents.
Most modern OCR systems are built on a type of AI architecture called a Transformer. These models work by having each new word "look back" at everything it has already generated. For a short document, that's fine. But for a long one? Things get ugly — fast.
Here's what happens as a document gets longer:
- Memory usage keeps growing — the model needs to remember more and more
- Speed slows down — every new word requires more computation
- GPU requirements spike — you need increasingly powerful (and expensive) hardware
- Page-by-page workarounds — most systems just give up and process one page at a time, resetting memory after each page
As the official Baidu research paper puts it: "No existing model can even parse ten pages in a single forward pass." Instead, they all resort to a "for-loop" approach — process page 1, forget it, process page 2, forget it... and so on. It works, but it's an engineering hack, not a real solution.
The Insight: Humans Don't Work That Way
Here's where Baidu's researchers got clever. They asked a simple question: How do humans read and copy long documents?
Think about it. When you're manually transcribing a book, you don't re-read every single word you've already written before writing the next one. Instead, you:
- Keep the original document in front of you
- Glance at the last few words you just wrote
- Write the next word
That's it. Older content naturally fades from your working memory. You don't need to remember page 1 when you're on page 47.
This human-like behavior inspired the core innovation behind Unlimited OCR.
The Solution: Reference Sliding Window Attention (R-SWA)
The magic behind Unlimited OCR is a new attention mechanism called Reference Sliding Window Attention, or R-SWA for short.
Think of "attention" as the model's ability to focus on relevant information. Traditional OCR models have full attention — they look at everything they've ever generated. R-SWA is smarter:
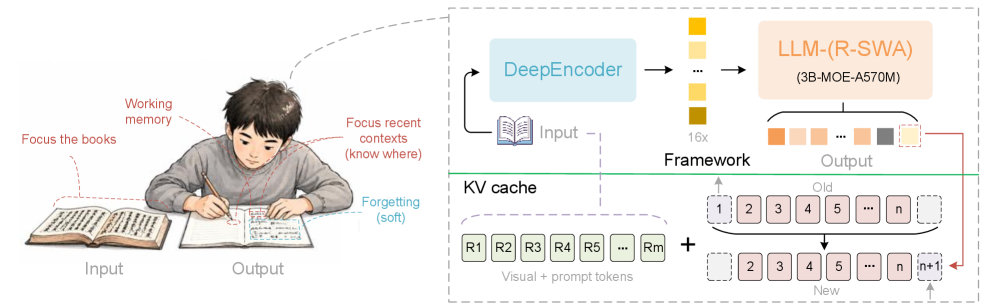
Figure: Reference Sliding Window Attention (R-SWA) — the decoder retains full access to compressed document reference tokens while attending only to a fixed sliding window of recently generated text (~128 tokens), keeping KV cache size constant during long-document decoding.
| What the model looks at | Traditional OCR | Unlimited OCR (R-SWA) |
|---|---|---|
| Original document image | Yes — Always | Yes — Always |
| Recently generated text | Yes — Yes | Yes — Yes (last ~128 tokens) |
| All previously generated text | Yes — grows forever | No — stays fixed |
Instead of an ever-growing memory, R-SWA keeps a small, fixed window of recent output (128 tokens by default) while always retaining full access to the original document image. The key insight is that the visual/reference tokens (the document image) are never subjected to recurrent state updates — this prevents the image from getting "blurry" or degraded over time, which is a problem with older sliding window approaches.
Solving the KV Cache Problem
If you've heard of the "KV Cache" problem in AI, this is where Unlimited OCR really shines. The KV Cache is essentially the model's short-term memory storage. In traditional transformers, it grows with every token generated.
Traditional OCR:
More output → Bigger KV Cache → More GPU memory → Slower inference
Unlimited OCR:
More output → Same KV Cache size → Stable memory → Consistent speed
By keeping the KV cache at a constant size throughout the entire decoding process, Unlimited OCR can process a 40-page document just as efficiently as a 2-page one.
Built on DeepSeek OCR: Standing on the Shoulders of Giants
Unlimited OCR wasn't built from scratch. Baidu used DeepSeek OCR as its foundation and made two key architectural improvements:
DeepEncoder (Kept from DeepSeek OCR)
This component compresses document images into a very small number of visual tokens. For example, a 1024×1024 image gets compressed into just 256 visual tokens. This aggressive compression is what allows the model to handle large documents without exploding in size.
MoE Decoder (Upgraded with R-SWA)
The decoder uses a Mixture-of-Experts (MoE) architecture with:
- 3 billion total parameters
- Only 500 million active parameters during inference (keeping it lean and fast)
- Every attention layer replaced with R-SWA
The result? A model that is both more efficient and more accurate than its predecessor.
The Results: Better AND Faster
Here's the part that usually doesn't happen in AI research: the efficiency improvement also came with an accuracy boost.
- 93% score on OmniDocBench v1.5 — a popular document parsing benchmark
- +6% improvement over the DeepSeek OCR baseline
- ~35% faster throughput on long documents compared to DeepSeek OCR
- Successfully parsed documents of 2, 5, 10, 20, and 40+ pages in a single forward pass
The improvements span across all document types:
- Plain text recognition
- Mathematical formula extraction
- Table understanding
- Reading order prediction
Why This Matters Beyond OCR
Perhaps the most exciting part of this research is that R-SWA is not just for OCR. The Baidu team explicitly states it's a general-purpose attention mechanism applicable to:
- Automatic Speech Recognition (ASR) — transcribing long audio recordings
- Translating long documents end-to-end
- Any task involving long-horizon parsing of reference-based inputs
This could be a foundational building block for the next generation of AI models that handle long-form content.
How to Try Unlimited OCR
The model is fully open-source and available right now:
- GitHub: github.com/baidu/Unlimited-OCR
- Hugging Face: huggingface.co/baidu/Unlimited-OCR
- Live Demo: Available on Hugging Face Spaces
- Research Paper: arxiv.org/abs/2606.23050
You can run it with just a few lines of Python using the Hugging Face transformers library.
Conclusion: A New Era of Document AI
Baidu's Unlimited OCR is more than just a better OCR tool. It's a rethinking of how AI models should handle long-horizon tasks — by mimicking the way human working memory actually functions, rather than brute-forcing through unlimited context windows.
For businesses dealing with large document archives, legal firms processing contracts, researchers digitizing books, or anyone who's ever been frustrated by page-limit restrictions in OCR tools — this is a genuine game-changer.
The era of one-shot, full-document parsing has arrived.
References
- Baidu Inc. (2026). Unlimited OCR Works: Welcome the Era of One-shot Long-horizon Parsing. arXiv:2606.23050. https://arxiv.org/html/2606.23050v1
- Baidu. Unlimited-OCR Model Card. Hugging Face. https://huggingface.co/baidu/Unlimited-OCR
- Mehul Gupta (2026). Baidu's Unlimited OCR: Beats DeepSeek OCR, Parses entire book in one go. Data Science in Your Pocket, Medium. https://medium.com/data-science-in-your-pocket/baidus-unlimited-ocr-beats-deepseek-ocr-parses-entire-book-in-one-go-6e3e1a8c9b34
- Facebook post summary: Baidu has just broken one of the biggest limitations of current OCR. https://www.facebook.com/thanhhm/posts/10165163919113126/
Ready to Scale Document AI for Long-Form Content?
Need help deploying OCR, document parsing pipelines, or production RAG over large archives? Our team can guide you from proof-of-concept to enterprise-grade document AI.