GLM-5.2 Is Here — And It's Rewriting the Rules of Open-Source AI

The Short Version
On June 13, 2026, Z.ai — formerly known as Zhipu, one of China's legendary "six tigers" of AI — dropped GLM-5.2, its most powerful flagship model to date. This isn't a minor patch. It's a generational leap: a solid 1-million-token context window, a new sparse attention architecture, flexible thinking-effort levels, and a fully MIT open-source license with zero regional restrictions.
If you've been watching the AI space, you know how rare it is for an open-source model to genuinely threaten the closed-source frontier. GLM-5.2 does exactly that.
What Makes GLM-5.2 Special?
A Solid 1M-Token Context Window — Not Just a Marketing Claim
Every AI lab loves to brag about context length. Z.ai is the first to call out the difference between claiming 1M tokens and actually delivering it reliably under real engineering pressure.
GLM-5.2 doesn't just accept 1 million tokens — it sustains quality across long, messy, real-world coding-agent trajectories. That's a 5× jump from GLM-5.1's ~200,000-token window, and each response can return up to 131,072 output tokens.
"A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure."
In practice, this means a coding agent can hold an entire mid-sized repository in working memory — source files, tests, configs, conversation history — without the constant summarization that smaller windows force.
IndexShare: The Architecture That Makes 1M Context Affordable
This is the engineering story that doesn't get enough attention. GLM-5.2 introduces IndexShare, a new technique applied to its Dynamic Sparse Attention (DSA) layers. Every 4 transformer layers share a single lightweight indexer, reusing the same top-k indices across all four layers.
The result? A 2.9× reduction in per-token FLOPs at 1M context length — making long-context inference not just possible, but economically viable.
They also improved the MTP (Multi-Token Prediction) layer for speculative decoding, increasing acceptance length by up to 20%, which directly translates to faster responses.
Flexible Thinking Effort: High vs. Max
GLM-5.2 introduces two reasoning modes:
| Mode | Best For |
|---|---|
| High | Standard coding tasks, faster latency |
| Max | Complex multi-step engineering, maximum capability |
Z.ai recommends Max effort for challenging long-horizon tasks. In Claude Code, the /effort command maps directly to this setting.
The model's capability at comparable token budgets is roughly positioned between Claude Opus 4.7 and Claude Opus 4.8 — an extraordinary achievement for an open-source model.
Benchmark Performance: The Open-Source Crown, Reclaimed
Here's where it gets exciting. Beyond coding-specific suites, third-party rankings tell the same story:
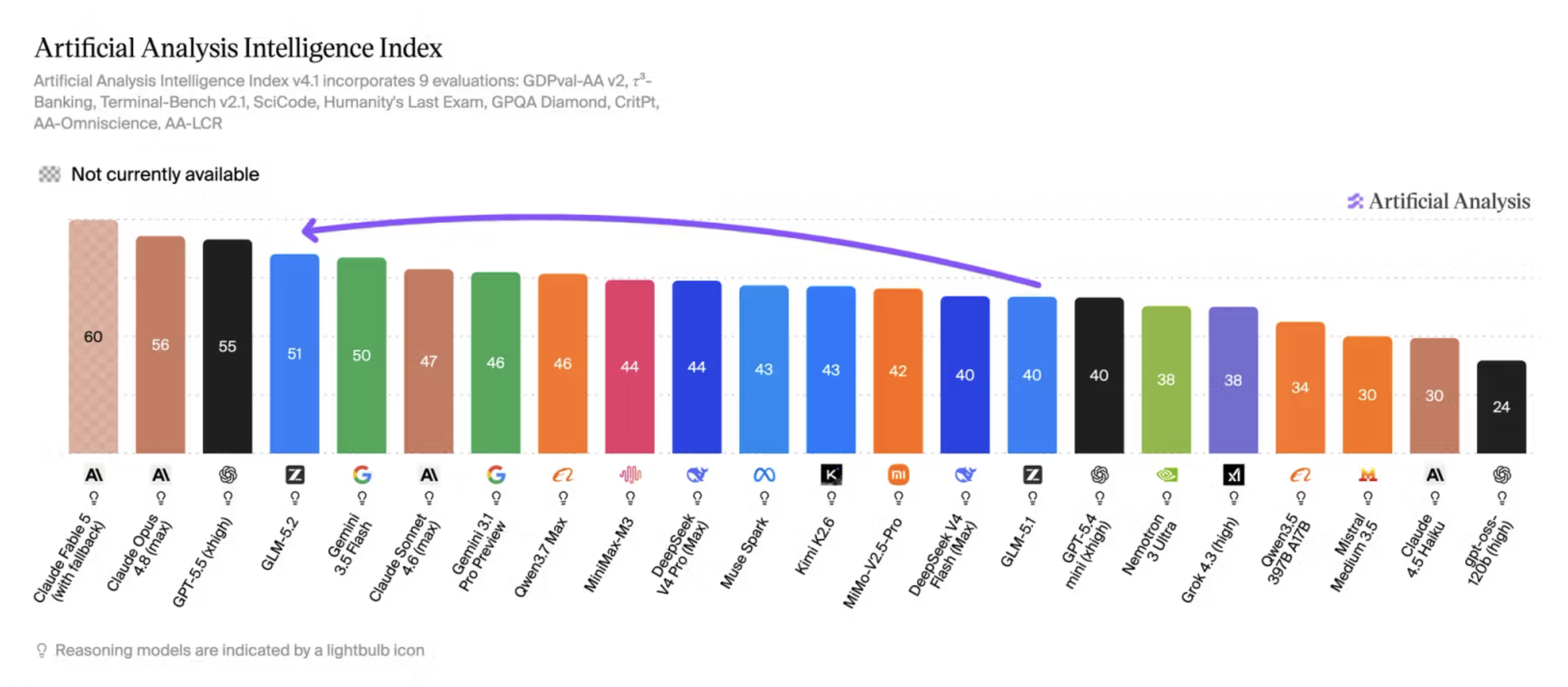
Figure: Artificial Analysis Intelligence Index (composite of nine evaluations). GLM-5.2 scores 51 — a +11 jump from GLM-5.1 (40) — ranking 4th overall, between Gemini 3.5 Flash (50) and Claude Opus 4.8 (56).
On long-horizon coding benchmarks:
- FrontierSWE (open-ended technical projects spanning hours): GLM-5.2 trails only Claude Opus 4.8 by 1%, while beating GPT-5.5 by 1% and Claude Opus 4.7 by 11%
- PostTrainBench (GPU-based post-training optimization): GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8
- Terminal-Bench 2.1: GLM-5.2 scores 81.0, up from GLM-5.1's 63.5 — and within striking distance of Claude Opus 4.8's 85.0
- SWE-bench Pro: 62.1 vs. GLM-5.1's 58.4
Fireworks AI independently validated GLM-5.2 on their own GPU stack and reproduced 91.4% on GPQA-Diamond (vs. Z.ai's reported 91.2%) — confirming these numbers aren't just vendor-optimized cherry-picks.
MIT License, No Regional Restrictions
This is a big deal. GLM-5.2 ships under a pure MIT open-source license — no regional limits, no access walls, no strings attached. Z.ai calls it "technical access without borders."
The open weights were made available shortly after launch, making GLM-5.2 immediately deployable by any developer, anywhere in the world.
Why This Could Move Z.ai's Stock on Thursday
Z.ai made history in early 2026 as the world's first large-model stock, listing on the Hong Kong Stock Exchange.
Here's why GLM-5.2 is a compelling catalyst for its share price:
- Velocity of innovation: Four flagship-tier releases in roughly four months (GLM-5, GLM-5-Turbo, GLM-5.1, GLM-5.2). This pace signals a team firing on all cylinders.
- Open-source moat: By releasing under MIT with no regional limits, Z.ai is aggressively building developer mindshare globally — the same playbook that made Meta's Llama a household name.
- Closing the gap on closed-source giants: When an open model beats GPT-5.5 on long-horizon benchmarks, it's not just a technical milestone — it's a commercial signal.
- Day-zero third-party validation: Fireworks AI's independent benchmark reproduction on launch day is rare and powerful social proof. It removes the "trust the vendor" asterisk.
- Enterprise-ready architecture: The IndexShare efficiency gains mean lower inference costs — a direct line to enterprise margin expansion.
The narrative is clean, the benchmarks are strong, and the open-source community is already buzzing. That's a recipe for attention — and attention moves stocks.
Where to Try GLM-5.2
- Z.ai GLM Coding Plan (Lite, Pro, Max, Team tiers) — live immediately at launch
- Fireworks AI — serverless inference, day zero, with full infrastructure control and zero data retention
- Hugging Face — open weights available under MIT license
Ready to Deploy GLM-5.2 in Production?
Need help evaluating GLM-5.2, choosing inference hosting, or integrating it into your coding-agent workflow? Our AI experts can guide model selection, deployment, and production pipelines.