RAG Is a Crutch — Parametric Knowledge Injection Just Threw It Away

A research team from Tsinghua University just solved one of AI's most stubborn problems — and the answer is more elegant than anyone expected.
Every AI Chatbot You've Ever Used Has Been Cheating
Here's something the AI industry doesn't advertise loudly: most AI assistants don't actually know things. Not really.
When you ask a modern AI chatbot a question about recent events, internal company documents, or specialised topics, it doesn't reach into a deep well of understanding. It either guesses from stale training data — sometimes confidently and wrongly — or it scrambles to look something up before answering. That second approach has a name: RAG, Retrieval-Augmented Generation. And for the past few years, it's been the industry's go-to band-aid for AI's knowledge problem.
RAG works like an open-book exam. The AI doesn't study. It just gets to bring notes. Before answering your question, it runs a search, grabs some relevant documents, reads them on the spot, and tries to summarise what it found. Every single time. For every single query.
It's functional. But it's a crutch. And a team of eight researchers from Tsinghua University — Baoqing Yue, Weihang Su, Qingyao Ai, Yichen Tang, Changyue Wang, Jiacheng Kang, Jingtao Zhan, and Yiqun Liu — just built something that throws that crutch away.
What's Wrong With the Crutch?
Before we get to the solution, let's be honest about why RAG falls short.
It's slow. Every query triggers a retrieval process before the AI can even begin thinking. You're waiting for a search engine before you get an answer.
It's shallow. The AI is reading, not learning. It has no deeper understanding of the retrieved material — it's just skimming notes it's never seen before and hoping for the best.
It's fragile. Wrong documents retrieved means wrong answers generated. Garbage in, garbage out — at search speed.
It's expensive at scale. Processing long retrieved documents for millions of queries adds up to enormous computational costs.
The obvious alternative — actually retraining the AI on new knowledge — sounds better but is often worse in practice. Retraining a large model takes weeks, costs a fortune in compute, and risks catastrophic forgetting: the model starts losing things it already knew as it absorbs new information. It's like sending your best employee back to university every time the company policy changes.
So the field has been stuck in an uncomfortable middle ground. RAG on one side — fast to update, but shallow. Retraining on the other — deep, but slow, expensive, and risky.
Parametric Knowledge Injection via DMoE is the exit from that dead end.
The Big Idea: Knowledge as Plug-In Modules
DMoE stands for Decoupled Mixture-of-Experts. The name sounds technical, but the concept is beautifully simple.
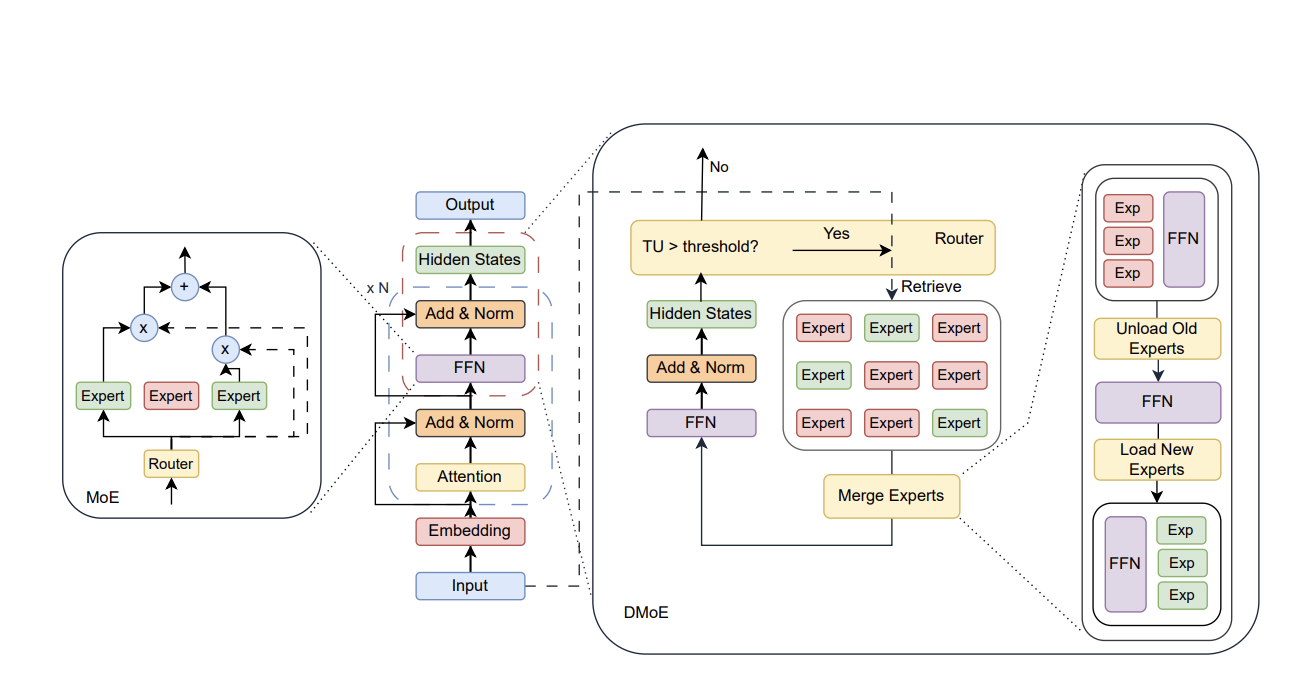
Figure 2: Dense model, traditional MoE, and DMoE side by side. Standard MoE replaces feed-forward layers with a coupled router-expert stack baked into the model. DMoE decouples both router and experts from the frozen base — at inference, it pulls in only the experts needed for knowledge injection, updating knowledge adaptively without touching what the model already knows.
Think of your AI as a highly skilled chef. Years of culinary training are baked into their instincts — that's the base model. Now you want the chef to also master Sichuan cuisine, French pastry, and vegan cooking.
The retraining way: Send the chef back to culinary school for six months. Expensive, slow, and they might forget some of their original skills in the process.
The RAG way: Hand the chef a cookbook every time they cook. They can follow the recipe, but they're not really a Sichuan chef. They're just a fast reader.
The DMoE way: Give the chef three short, focused training intensives — one per cuisine — and let them internalise each one as a separate, independent skill set. When a Sichuan dish is ordered, the Sichuan expertise activates. When a French dessert is needed, the pastry knowledge kicks in. The chef's core skills never change. New expertise is simply added alongside.
That's parametric knowledge injection. Each expert module is a small, lightweight piece of trained knowledge — built from a specific document, topic, or dataset — that lives outside the main AI model but gets genuinely absorbed into its parameters when called upon. Not read from a cheat sheet. Actually known.
Three Things That Make DMoE Special
The Core AI Is Never Touched
This is the headline. When you add new knowledge via DMoE, the base model is completely frozen. No retraining. No risk of forgetting. No downtime. No six-figure compute bill.
Each expert module is a tiny trained adapter — built using a technique called LoRA — that encodes one specific chunk of knowledge. Want to add the latest medical research? Train one small module. Want to update your company's internal policy? Swap that one module. Everything else stays exactly as it was. Adding knowledge is now as simple as installing an app.
The AI Knows When It Needs Help
DMoE doesn't blindly activate expert modules for every word it generates. That would defeat the purpose. Instead, it monitors its own confidence level in real time — token by token.
Think of it like a GPS that trusts its own maps most of the time, but automatically switches to live traffic data the moment it senses congestion ahead. The AI generates answers normally — and only reaches out to an expert module when it detects it's entering uncertain territory.
The technical measure of this is called Token Uncertainty — essentially the entropy of the AI's probability distribution over its next word:
When this uncertainty score crosses a threshold τ, the router fires. It runs a fast keyword search across all available expert modules, picks the most relevant ones, and brings them in. When confidence is high, the AI works alone. Clean, efficient, and smart.
One Clever Trick Keeps It Blazing Fast
Here's a problem the team had to solve elegantly. AI models use a speed mechanism called the KV-cache — a memory of what they've already processed, so they don't have to recompute it mid-answer. If you attach expert modules at multiple points throughout the AI's thinking process, you scramble that cache and lose the speed advantage entirely.
DMoE's solution: attach all expert knowledge only at the very final layer of the AI's processing pipeline. Everything before that final step stays cached and untouched. Expert knowledge layers in right at the end — like a specialist doing a final review of a document that's already been drafted, rather than rewriting every paragraph from scratch.
The result: deep, parameter-level knowledge integration — at near-standard inference speed.
The Numbers Don't Lie
The team tested DMoE on four rigorous knowledge benchmarks — HotpotQA, ComplexWebQuestions, Quasar-T, and StrategyQA — using two real-world AI models (Llama-3.2-1B-Instruct and Qwen2.5-1.5B-Instruct) as the base.
| What Was Measured | DMoE Result |
|---|---|
| Answer accuracy vs. base AI | Better across all 4 benchmarks |
| Speed vs. best RAG competitor (FLARE) | ~3× faster |
| GPU memory vs. traditional MoE backbone | 7–8 GB vs. 26 GB |
| Time per answer vs. traditional MoE | 2–4 seconds vs. 20+ seconds |
| Did it forget original knowledge? | Zero degradation detected |
Smarter. Faster. Cheaper. Safer. All at once.
What This Unlocks in the Real World
Healthcare
A hospital deploys one base AI model. Each department — cardiology, oncology, emergency medicine — gets its own expert module. Update the clinical guidelines for one specialty? Swap that one module. The rest of the system is completely unaffected.
Enterprise
Your company's AI assistant carries internal policies, product specs, and client history as modular knowledge packs. New quarter, new pricing sheet? One module update. No IT project. No retraining budget. No waiting.
News & Finance
Media companies and trading firms push fresh knowledge modules daily — giving their AI genuine awareness of current events without the cost or delay of continuous retraining.
Education
An AI tutor loads curriculum-specific modules per subject and grade level, activating only what's relevant to each student's question. Personalised, deep, and efficient — all from the same base model.
So Is RAG Actually Dead?
Not completely — and the researchers aren't claiming it is.
RAG still makes sense when you need to search across a truly massive, unpredictable, constantly changing corpus — like the open web. For that kind of broad retrieval, a search engine remains the right tool.
But for structured, domain-specific, or proprietary knowledge that you want an AI to genuinely know rather than just look up — DMoE is a fundamentally better answer. It's the difference between an AI that carries a library card and one that has actually read the books.
RAG was always a workaround. Parametric Knowledge Injection is the real solution.
What's Still Being Worked On
The team is honest about the open questions. The current routing system uses keyword matching (BM25) — fast and practical, but it doesn't always capture the full meaning of a query. Future versions could use smarter semantic search for routing. Managing very large expert libraries — potentially thousands of modules — will need new organisational tools. And while single-layer attachment is great for speed, multi-layer expert integration could unlock even richer knowledge depth down the road.
The Bottom Line
AI has always had a knowledge expiry date stamped on it at birth. Every model knows everything up to its training cutoff — and nothing reliably after.
RAG tried to fix this by handing the AI a search engine. It helped. But it was always a crutch — and everyone in the field knew it.
DMoE throws that crutch away. New knowledge gets packaged into lightweight modules, plugged in on demand, and genuinely absorbed at the parameter level — without touching the base model, without running a retrieval pipeline, and without spending months retraining.
The Tsinghua team has built something that sounds almost too clean when you describe it simply. But the benchmarks are real, the architecture is published, and the results speak for themselves. Parametric Knowledge Injection is no longer a research fantasy. It's a working system — and it just made RAG look very, very tired.
Sources
- Yue, B., Su, W., Ai, Q., Tang, Y., Wang, C., Kang, J., Zhan, J., & Liu, Y. (2026). Decoupled Mixture-of-Experts for Parametric Knowledge Injection. arXiv:2606.14243. https://arxiv.org/abs/2606.14243
- arXiv Full Paper HTML. https://arxiv.org/html/2606.14243
- The Moonlight — Literature Review. https://www.themoonlight.io/en/review/decoupled-mixture-of-experts-for-parametric-knowledge-injection